Прорив чи ілюзія? Учені заявили про новий спосіб поліпшення ШІ, але є нюанс
 Дослідники знайшли можливий спосіб масштабування ШІ без додаткового навчання (фото: Freepik)
Дослідники знайшли можливий спосіб масштабування ШІ без додаткового навчання (фото: Freepik)
Нещодавно дослідники презентували один із нових законів "масштабування", який, за їхніми словами, здатен значно покращити ШІ. Однак, попри гучні заяви, експерти скептично налаштовані щодо реальної ефективності цього підходу.
У чому полягає метод і чому багато фахівців залишаються в роздумах, розповідає РБК-Україна (проект Styler) з посиланням на сайт новин у сфері технологій TechCrunch.
- Як закони масштабування ШІ можуть змінити індустрію?
- Що таке пошук на етапі виконання і як він працює?
- Сумніви з боку експертів
- ШІ-індустрія в пошуках нових методів масштабування
Як закони масштабування ШІ можуть змінити індустрію?
Закони масштабування ШІ - це неформальне поняття, що описує, як покращується продуктивність моделей ШІ в міру збільшення розмірів навчальних наборів даних і обчислювальних потужностей.
До минулого року домінуючим підходом було масштабування переднавчання - створення розширених моделей, які навчаються на дедалі більших обсягах даних. Цей принцип застосовували більшість провідних лабораторій у сфері ШІ.
Хоча переднавчання, як і раніше, актуальне, з'явилися два додаткові закони масштабування:
- Масштабування пост-навчання - налаштування поведінки моделі після основного етапу навчання
- Масштабування на етапі виконання - використання додаткових обчислень під час роботи моделі для посилення її "логічних" здібностей.
Нещодавно дослідники з Google і Каліфорнійського університету в Берклі запропонували те, що деякі коментатори назвали четвертим законом - пошук на етапі виконання (inference-time search).
Що таке пошук на етапі виконання і як він працює?
Цей метод дає змогу моделі генерувати одразу безліч можливих відповідей на запит і потім обирати серед них найкращу.
Дослідники стверджують, що такий підхід може підвищити продуктивність навіть застарілих моделей. Наприклад, Google Gemini 1.5 Pro нібито перевершив модель OpenAI o1-preview у тестах з математики та природничих наук.
"Просто вибравши випадкові 200 відповідей і перевіривши їх самостійно, Gemini 1.5 - стародавня за мірками ШІ-модель початку 2024 року - обходить o1-preview і наближається до o1", - написав у X (Twitter) один з авторів дослідження, докторський стипендіат Google Ерік Чжао.
Він також зазначив, що "самоперевірка" стає простішою при збільшенні масштабів. Інтуїтивно здається, що чим більше рішень розглядає модель, тим складніше вибрати правильне, але на практиці все навпаки.
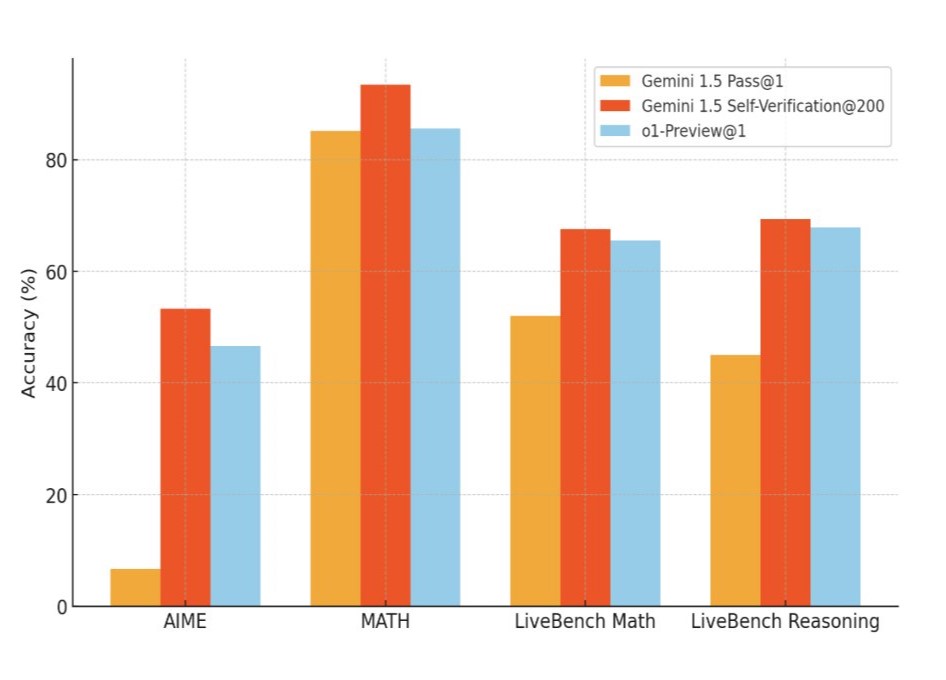
 Gemini 1.5, більш рання модель, вибравши і перевіривши 200 відповідей, перевершує o1-Preview і наближається до o1 (фото: X/@ericzhao28)
Gemini 1.5, більш рання модель, вибравши і перевіривши 200 відповідей, перевершує o1-Preview і наближається до o1 (фото: X/@ericzhao28)
Сумніви з боку експертів
Незважаючи на такі заяви, низка дослідників вважають, що метод пошуку на етапі виконання не універсальний і здебільшого марний.
За словами Меттью Гуздіала, дослідника ШІ та доцента Університету Альберти, цей метод ефективний лише тоді, коли можна чітко визначити, яка відповідь є найкращою.
"Якщо ми не можемо запрограмувати чіткі критерії правильної відповіді, то пошук на етапі виконання марний. Для звичайної взаємодії з мовною моделлю це не працює. Це не найвдаліший підхід для вирішення більшості завдань", - зазначив він.
З ним згоден Майк Кук, науковий співробітник Королівського коледжу Лондона. Він підкреслив, що цей метод не покращує процес логічного висновку в моделі, а лише допомагає обходити її обмеження.
"Пошук на етапі виконання не робить модель "розумнішою". Це всього лише спосіб обійти недоліки технологій, які можуть робити помилки, але робити це з повною впевненістю. Логічно, що якщо модель помиляється в 5% випадків, то, перевіривши 200 спроб рішення, ми швидше помітимо помилки", - сказав Кук.
ШІ-індустрія в пошуках нових методів масштабування
Обмеження методу пошуку на етапі виконання навряд чи потішать AI-індустрію, яка прагне поліпшити логічні здібності моделей за мінімальних витрат обчислювальних потужностей.
Як зазначають дослідники, сучасні моделі, орієнтовані на "логічне мислення", можуть витрачати тисячі доларів обчислювальних ресурсів на розв'язання однієї математичної задачі.
Поки що пошук нових методів масштабування триває.
Вас може зацікавити:
- Як сучасні технології могли б розкрити вбивство Кеннеді
- Головні міфи про ШІ, у які досі вірять мільйони людей
- Як ШІ переверне ігрову індустрію в найближчі роки

